
For all the hype surrounding large language models and their ability to generate human-like text, one of the most persistent and vexing problems in enterprise AI remains deceptively simple: chatbots forget. They forget what you said two minutes ago. They forget your preferences. They forget the context that makes a conversation feel like a conversation rather than a series of disconnected exchanges. Google Cloud is now offering a detailed architectural blueprint for solving this problem, and the implications for businesses building AI-powered customer interactions are significant.
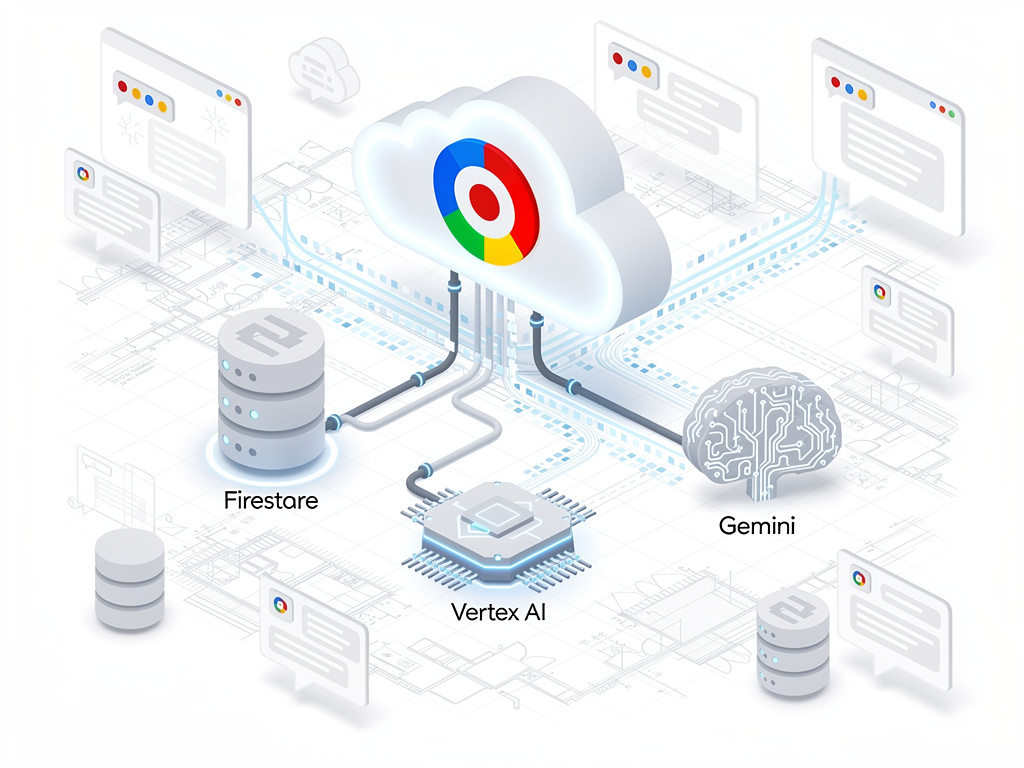
In a technical blog post published on the Google Cloud Blog, engineers outlined a comprehensive approach to improving chatbot memory using a combination of Google Cloud services, including Firestore, Vertex AI, and the Gemini family of models. The post goes beyond theoretical hand-waving and provides concrete implementation patterns that enterprise developers can adopt immediately. The core thesis is straightforward: a chatbot that remembers is a chatbot that converts, retains, and satisfies.
The Memory Problem That Costs Enterprises Millions
The fundamental challenge is that most large language models are stateless by design. Each API call to a model like Gemini or GPT-4 is independent. The model has no inherent mechanism for recalling what happened in a previous turn of conversation, let alone a previous session from last week. This means that without explicit engineering, a customer who tells a support chatbot their account number at the start of a conversation may be asked for it again moments later—a frustrating experience that erodes trust and drives users toward human agents, which are far more expensive to operate.
Google Cloud’s approach addresses this through what it describes as a layered memory architecture. The system distinguishes between short-term memory (the current conversation context), long-term memory (information persisted across sessions), and entity memory (structured facts about users, products, or other domain-specific objects). Each layer serves a different purpose and requires different storage and retrieval strategies. This is not a novel concept in computer science—operating systems have used similar memory hierarchies for decades—but applying it systematically to conversational AI at enterprise scale is where the engineering complexity lies.
How Firestore and Vertex AI Work Together
At the heart of Google’s proposed architecture is Firestore, its serverless NoSQL document database. Firestore serves as the persistent memory store, holding conversation histories, user profiles, and extracted entities in a schema-flexible format that can accommodate the varied and often unpredictable nature of conversational data. According to the Google Cloud Blog, Firestore’s real-time synchronization capabilities make it particularly well-suited for this use case, as chatbot memory needs to be both written and read with minimal latency.
Vertex AI, Google Cloud’s machine learning platform, handles the intelligence layer. The system uses Vertex AI to run Gemini models that process incoming user messages, extract relevant entities and facts, determine what should be committed to long-term memory, and retrieve relevant context from previous interactions when formulating responses. The retrieval step is especially important: rather than stuffing the entire conversation history into the model’s context window—which would be both expensive and eventually impossible as histories grow—the system uses vector search to find the most relevant prior exchanges and facts.
Vector Search and the Art of Selective Recall
Vector search is the technical mechanism that makes intelligent memory retrieval feasible. When a user sends a message, the system converts it into a numerical representation (an embedding) and then searches the memory store for previously stored embeddings that are semantically similar. This means the chatbot doesn’t just look for keyword matches—it understands conceptual similarity. A user asking about “my last order” can be matched to a stored memory about a specific purchase even if the exact words differ.
Google Cloud’s implementation uses Vertex AI’s embedding models to generate these vector representations and Firestore’s vector search capabilities to perform the retrieval. This is a notable architectural choice. While many developers have turned to dedicated vector databases like Pinecone or Weaviate for this purpose, Google is making the case that Firestore can handle both traditional document storage and vector search in a single service, reducing operational complexity. Whether this approach scales as effectively as purpose-built vector databases under heavy production loads remains an open question that enterprises will need to benchmark for their specific workloads.
The Summarization Strategy for Long Conversations
One of the more practical insights from the Google Cloud technical guide is the use of summarization to manage context window limitations. Even the largest context windows available today—Gemini 1.5 Pro supports up to one million tokens—will eventually be overwhelmed by a sufficiently long conversation history or a sufficiently active user with years of interaction data. The solution is to periodically summarize older portions of the conversation and store the summary rather than the raw transcript.
This summarization is itself performed by the Gemini model, creating an interesting recursive pattern: the AI summarizes its own past conversations so that its future self can recall the key points without needing the full record. The Google Cloud Blog notes that this approach must be implemented carefully to avoid information loss. Critical details—such as a customer’s stated preferences, unresolved complaints, or specific product configurations—need to be preserved even when surrounding conversational filler is compressed. The engineering team recommends using structured extraction alongside summarization to ensure that key entities and facts are stored independently of the narrative summaries.
Enterprise Implications: From Support Bots to Sales Agents
The business case for improved chatbot memory extends well beyond customer support. Sales-oriented chatbots that remember a prospect’s industry, company size, and previously expressed pain points can deliver dramatically more relevant product recommendations. Healthcare chatbots that recall a patient’s medication history and symptom timeline can provide more informed triage guidance. Financial services bots that remember a client’s risk tolerance and portfolio composition can offer more personalized advisory interactions.
According to recent reporting from Reuters, enterprise spending on conversational AI infrastructure is accelerating in 2025, with companies increasingly moving beyond proof-of-concept deployments to production systems that handle millions of interactions per month. In this context, memory management is not a nice-to-have feature—it is a core requirement that directly impacts user satisfaction metrics, resolution rates, and ultimately revenue. Companies that fail to implement effective memory systems risk building chatbots that feel perpetually amnesiac, undermining the very efficiency gains that motivated the AI investment in the first place.
The Competitive Pressure From OpenAI and Microsoft
Google Cloud’s detailed guidance on chatbot memory arrives at a moment of intense competition in the enterprise AI platform market. OpenAI has been building out its own memory features for ChatGPT and its API offerings, allowing models to retain information across conversations when users opt in. Microsoft, through its Azure OpenAI Service and Copilot products, has been integrating persistent memory and personalization features into its enterprise AI stack. Amazon Web Services has similarly been expanding the memory and state management capabilities of its Bedrock platform for building generative AI applications.
What distinguishes Google’s approach, at least as presented in this technical blog, is the degree of architectural specificity. Rather than offering memory as a black-box feature, Google is showing developers exactly how to build it using composable cloud services. This appeals to a particular segment of the enterprise market—organizations with strong engineering teams that want control over their AI architecture rather than relying on opaque platform features. It also, of course, ties those organizations more deeply into Google Cloud’s service portfolio, creating the kind of infrastructure lock-in that all cloud providers seek.
Privacy, Data Retention, and the Regulatory Dimension
Any system that stores and recalls user conversation data raises immediate questions about privacy and regulatory compliance. The Google Cloud architecture stores potentially sensitive information in Firestore, which means enterprises must configure appropriate access controls, encryption, and data retention policies. In jurisdictions governed by the GDPR, CCPA, or sector-specific regulations like HIPAA, the ability to delete specific user memories on request is not optional—it is a legal requirement.
The technical blog does not extensively address these compliance considerations, which is a notable gap. Enterprises implementing this architecture will need to build their own data governance layers on top of it, including mechanisms for users to view, correct, and delete their stored memories. This is a non-trivial engineering effort that adds to the total cost of ownership. As AI regulation continues to tighten globally, the memory systems that enterprises build today will need to be flexible enough to accommodate rules that have not yet been written.
What Comes Next for Conversational AI Memory
The trajectory of chatbot memory development points toward increasingly sophisticated systems that blur the line between a tool and a relationship. Future implementations will likely incorporate emotional context—recognizing not just what a user said, but how they said it and what emotional state they appeared to be in. They will integrate with broader enterprise data systems, pulling in CRM records, purchase histories, and support tickets to create a unified understanding of each user that goes far beyond what any single conversation could reveal.
Google Cloud’s architectural blueprint represents a solid foundation for this future, but it is only a foundation. The companies that build the most effective conversational AI systems will be those that combine sound technical architecture with thoughtful design choices about what to remember, what to forget, and how to use stored knowledge in ways that feel helpful rather than intrusive. In an era where AI interactions are becoming a primary interface between businesses and their customers, getting memory right is not just an engineering challenge—it is a strategic imperative.

