
As enterprises rush to deploy artificial intelligence agents across their operations, a costly blind spot is emerging that threatens to derail digital transformation initiatives: the substantial and often underestimated expense of evaluating and testing these autonomous systems. While organizations meticulously budget for development, infrastructure, and licensing fees, many are discovering too late that the non-deterministic nature of AI agents creates an ongoing financial burden that can eclipse initial deployment costs.
According to CIO.com, organizations embracing AI agents frequently fail to estimate the costs associated with testing their output, a challenge compounded by the unpredictable nature of generative AI responses. Unlike traditional software that produces consistent results given identical inputs, AI agents can generate different outputs each time they process the same query, necessitating continuous evaluation frameworks that demand significant resources in both human expertise and computational power.
The financial implications extend far beyond simple quality assurance. Companies are finding themselves in a perpetual cycle of testing, refinement, and re-testing as AI models evolve and adapt to new data. This iterative process requires dedicated teams of data scientists, machine learning engineers, and domain experts who must validate not only the accuracy of agent responses but also their alignment with corporate policies, regulatory requirements, and ethical standards. The cost of maintaining these specialized teams, particularly in a competitive talent market, can quickly spiral into millions of dollars annually for large enterprises.
The Determinism Dilemma: Why Traditional Testing Frameworks Fall Short
Traditional software testing methodologies, built on the foundation of deterministic systems, prove inadequate when applied to AI agents. A conventional application will consistently produce output ‘B’ when given input ‘A,’ allowing quality assurance teams to establish clear pass-fail criteria. AI agents, however, operate in a probabilistic space where the same input might yield multiple valid yet different responses, each requiring evaluation for accuracy, appropriateness, and potential risks.
This fundamental shift demands entirely new evaluation frameworks. Organizations must develop comprehensive testing suites that assess not just correctness but also consistency, bias, hallucination rates, and adherence to guardrails. Each dimension requires different expertise and tools, multiplying the complexity and cost of the evaluation process. Companies are discovering that they need to run thousands of test cases across various scenarios, with each iteration requiring human review to validate results that cannot be automatically verified.
Building the Infrastructure: The Technology Stack Behind Agent Testing
The technical infrastructure required to properly evaluate AI agents represents another significant cost center. Organizations must invest in specialized platforms for logging agent interactions, creating synthetic test datasets, running parallel evaluations, and tracking performance metrics over time. These systems need to operate at scale, handling potentially millions of agent interactions while maintaining detailed audit trails for compliance purposes.
Moreover, the evaluation infrastructure must be dynamic, adapting as the AI agents themselves evolve. When models are updated or retrained, the entire testing suite must be re-executed to ensure that improvements in one area haven’t introduced regressions elsewhere. This continuous integration and continuous deployment (CI/CD) pipeline for AI requires sophisticated orchestration tools and substantial computational resources, particularly when evaluating large language models that demand significant GPU capacity.
The Human Element: Specialized Talent and Ongoing Training
Perhaps the most significant hidden cost lies in the human capital required to properly evaluate AI agents. Organizations need teams that combine deep technical knowledge of machine learning with domain expertise in the specific business functions the agents support. Finding individuals with this dual expertise commands premium compensation, and the scarcity of qualified candidates has created a bidding war among enterprises.
Beyond recruitment, companies must invest heavily in training existing staff to understand the nuances of AI evaluation. This includes not only technical training on evaluation frameworks and tools but also education on identifying subtle forms of bias, recognizing potential security vulnerabilities, and understanding the ethical implications of agent decisions. The ongoing nature of this training, as AI capabilities and best practices evolve, represents a continuous expense that many organizations failed to anticipate in their initial budgets.
Regulatory Compliance: The Accelerating Cost of Governance
As regulators worldwide turn their attention to AI systems, compliance requirements are adding another layer of evaluation costs. The European Union’s AI Act, for instance, mandates rigorous testing and documentation for high-risk AI systems, requiring organizations to maintain detailed records of how their agents were evaluated, what risks were identified, and how those risks were mitigated. Similar regulations are emerging in other jurisdictions, each with their own specific requirements.
Meeting these regulatory standards demands not only technical evaluation but also extensive documentation, third-party audits, and ongoing monitoring. Companies must establish governance frameworks that track agent performance in production, detect drift from expected behaviors, and provide rapid response capabilities when issues arise. The cost of building and maintaining these governance structures, including legal reviews and external audits, can easily reach into the hundreds of thousands of dollars annually for organizations deploying multiple AI agents.
The Production Paradox: When Deployment Multiplies Testing Needs
A particularly insidious aspect of AI agent evaluation costs emerges after deployment. While pre-production testing is expensive, organizations are discovering that monitoring agents in production environments requires even greater investment. Real-world usage patterns often reveal edge cases and failure modes that weren’t anticipated during testing, necessitating rapid response teams and continuous evaluation processes.
The stakes are higher in production, where agent errors can directly impact customers, damage brand reputation, or create legal liabilities. Companies must implement real-time monitoring systems that can detect problematic agent behaviors before they cause significant harm, along with rollback mechanisms to quickly revert to previous versions when issues arise. This operational overhead, combined with the need for 24/7 monitoring capabilities, substantially increases the total cost of ownership for AI agent deployments.
Quantifying the Impact: What Organizations Are Actually Spending
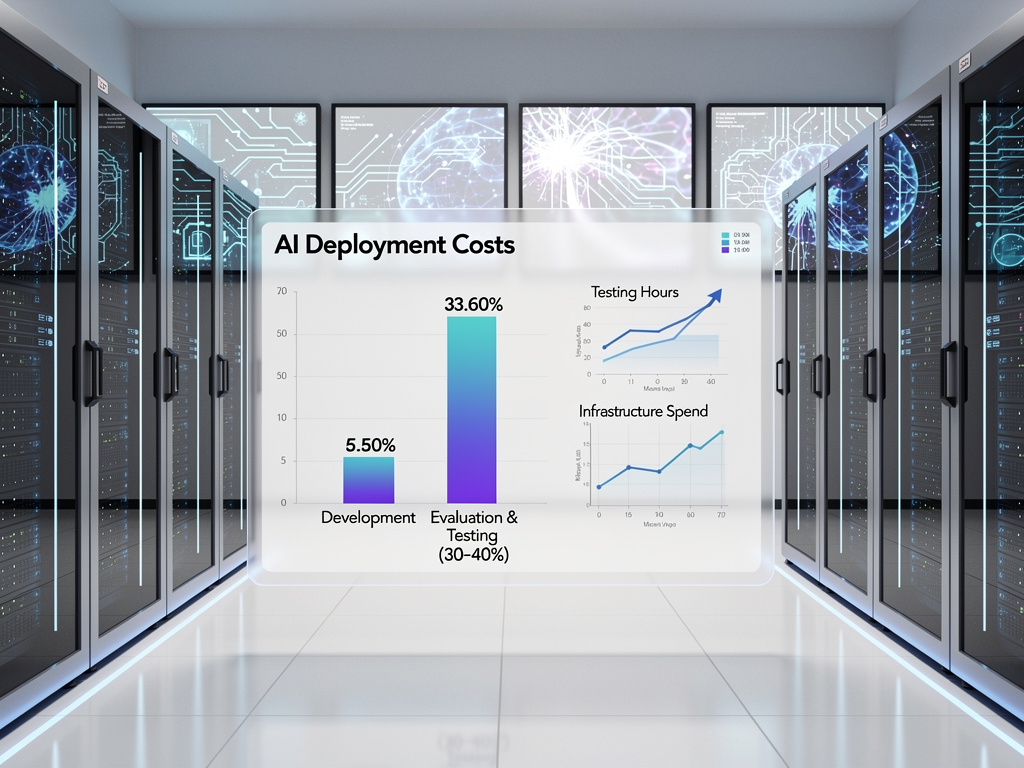
While many organizations remain reluctant to publicly disclose their AI evaluation costs, industry analysts estimate that testing and quality assurance can consume 30-40% of the total cost of an AI agent deployment over its lifetime. For a major enterprise deploying multiple agents across different business functions, this can translate to tens of millions of dollars in evaluation-related expenses that weren’t included in initial business cases.
The situation is particularly acute for organizations in highly regulated industries such as financial services and healthcare, where the consequences of AI errors are severe. These companies often find themselves spending more on evaluation and monitoring than on the initial development of the agents themselves, a ratio that would be unthinkable in traditional software projects but has become the new reality of AI deployment.
Strategic Responses: How Leading Organizations Are Addressing the Challenge
Forward-thinking organizations are beginning to develop more sophisticated approaches to managing AI evaluation costs. Some are investing in automated evaluation frameworks that can reduce the need for constant human review, using one AI system to evaluate the outputs of another. While this approach introduces its own complexities, it can significantly reduce the marginal cost of each evaluation cycle.
Others are adopting a more conservative deployment strategy, starting with narrowly scoped agents in low-risk applications where evaluation requirements are less stringent. This allows organizations to build expertise and refine their evaluation processes before tackling more complex, mission-critical deployments. Additionally, some companies are forming industry consortiums to share evaluation frameworks and best practices, distributing the cost of developing robust testing methodologies across multiple organizations.
The Path Forward: Integrating Evaluation into the Development Lifecycle
The most successful organizations are those that have integrated evaluation considerations into their AI development process from the beginning, rather than treating testing as an afterthought. This means involving evaluation experts in the design phase, building testability into agent architectures, and establishing clear metrics for success before development begins. By making evaluation a first-class concern throughout the development lifecycle, companies can avoid costly rework and ensure that their agents meet quality standards from day one.
This shift requires a fundamental change in how organizations approach AI projects. Instead of focusing solely on capabilities and features, successful AI initiatives now balance functionality with evaluability, recognizing that an agent that cannot be reliably tested is an agent that cannot be safely deployed. This more mature approach to AI development, while initially more expensive, ultimately reduces total cost of ownership by preventing the accumulation of technical debt and reducing the risk of costly failures in production.
As the AI agent market continues to mature, organizations that fail to account for evaluation costs in their planning face significant risks. Budget overruns can derail promising initiatives, while inadequate testing can lead to agent failures that damage customer relationships and brand value. The hidden costs of AI agent deployment are becoming increasingly visible, forcing enterprises to develop more realistic and comprehensive budgeting models that reflect the true expense of bringing these powerful but unpredictable systems into production environments.

