
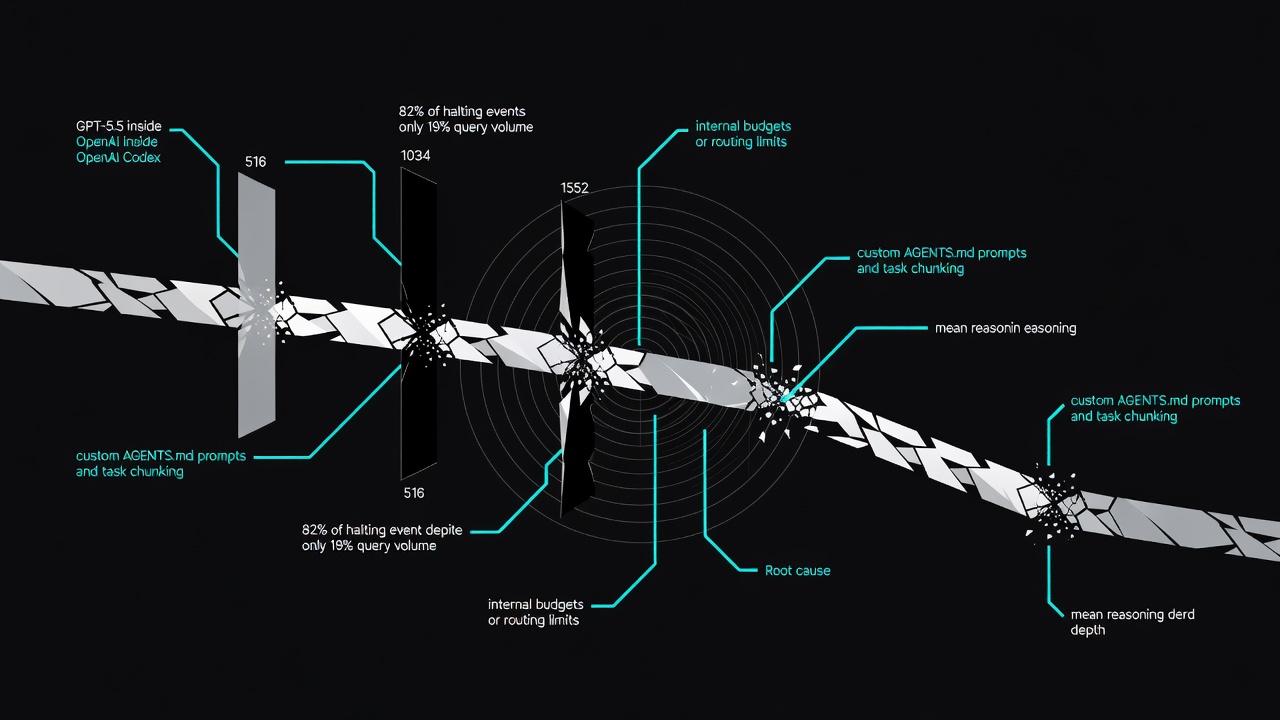
Developers counting on OpenAI’s latest coding agent for tough assignments have run into an odd pattern. Responses from GPT-5.5 inside Codex often halt at very specific reasoning token levels. The numbers 516, 1034 and 1552 keep showing up. And the output suffers.
Data pulled from thousands of sessions paints a clear picture. One analysis of 390,195 response records spanning February to June 2026 reveals GPT-5.5 makes up just 19.3 percent of queries yet accounts for 82 percent of all exact-516 reasoning token events. That disproportion stands out. Mean reasoning tokens per response have also slid from 268 down to 107 over the period. The GitHub issue flags this as a potential bug tied to model behavior and rate limits.
Users describe the symptoms in blunt terms. Tasks that once wrapped up cleanly now produce shallow answers. The model stops mid-thought. Code suggestions contain basic errors. Complex refactoring jobs that demanded careful step-by-step logic end abruptly with incomplete patches. One developer noted on X that 82 percent of responses stopping at exactly 516 tokens come from GPT-5.5 despite its smaller share of traffic. The post linked back to the same issue thread.
But why these exact figures? The clustering at fixed boundaries hints at an internal mechanism at work. Perhaps a hidden reasoning budget. Or scheduling logic that routes queries to lighter compute paths under load. OpenAI has not offered a public explanation. Employees have asked some reporters for session IDs and feedback tokens to investigate further. The thread now carries 21 comments and 37 reactions. It stays open.
This comes at a moment when Codex sits at the center of many engineering workflows. The tool promises to write features, fix bugs, propose pull requests and even run tests inside containers. OpenAI introduced it last year with strong claims around agent capabilities. Its announcement page highlights how Codex reads AGENTS.md files placed in repositories. These plain text guides tell the agent about coding conventions, testing commands and project structure. The files act like a persistent set of instructions that apply across the directory tree.
Frustrated users have started to fight back with their own AGENTS.md tweaks. One common addition reads simply: “Spend time on thinking; you do not need to use the commentary channel to report progress to me.” The hope is to discourage early termination and force deeper internal reasoning. Chinese-language discussions on Facebook and CSDN have spread similar workarounds. Developers there call the phenomenon “降智” or intelligence drop. A recent CSDN article posted just hours ago summarizes user reports and points straight to the GitHub thread for evidence. That piece notes how prompts that once succeeded now require multiple revisions and produce lower quality code.
The token data gets even more specific when examined at the individual level. One user’s personal logs covering nearly 40,000 GPT-5.5 events showed an average of only 119 reasoning tokens. The 90th percentile hit 516 exactly in many cases. Spikes appeared at 1034, 1552 and 2070 as well. Other models in the family displayed smoother distributions with higher averages. GPT-5.4 averaged 402 tokens. The older codex-auto-review variant barely reached 40. These patterns suggest the issue ties closely to the GPT-5.5 variant rolled out for high and xhigh effort modes.
Reddit communities have lit up with parallel complaints. Threads in r/codex describe the 516 token wall appearing most often on the Pro plan when users select high or xhigh settings. One detailed post from late June laid out the statistical tables and urged others to contribute their logs. “This does not prove hidden reasoning truncation by itself,” the author wrote. “But it is a very strong model-specific telemetry anomaly.” The community has grown impatient. Several posters say they have switched to Claude-based tools after repeated disappointments.
Related problems compound the frustration. Separate GitHub reports detail SSD wear from excessive logging, desktop freezes on Windows, and frequent connection timeouts. A Reddit analysis warned that default TRACE-level logging to a local SQLite file can write hundreds of terabytes per year. One user measured 37 terabytes in just 21 days. That issue remains unresolved months after first reports. Capacity constraints during peak demand add another layer of instability. When servers strain, the model appears more likely to hit these artificial token caps.
OpenAI’s own documentation for GPT-5.5 encourages shorter, outcome-focused prompts. The company says the model performs best when users describe desired results, constraints and evidence rather than dictate every process step. Legacy instructions carried over from earlier versions can add noise and narrow the search space. Yet many Codex users rely on detailed system prompts and AGENTS.md files precisely because the agent operates autonomously inside codebases. The tension is obvious. Clearer guidance helps. Too much of it may trigger the very early stopping behavior people observe.
Developers have responded with creative defenses. Some instruct the model explicitly to ignore the 516 token limit if it appears. Others break large tasks into smaller verifiable steps and chain them manually. A GitHub repository collecting AGENTS.md patterns recommends instructions focused on context discipline, safer command execution and validation loops. The patterns aim to reduce token waste and prevent prompt injection risks. Early testers report modest gains but no complete fix.
The broader picture raises questions about how frontier models handle reasoning under the hood. If internal budgets or routing decisions create these hard clusters, then performance on hard problems will suffer predictably. Complex tasks need room to explore multiple paths, backtrack and synthesize. Truncation at fixed points short-circuits that process. Whether the root cause sits in inference scheduling, token allocation or something else, the data shows a measurable regression from earlier behavior.
So far OpenAI has treated the matter as a debugging exercise rather than a public acknowledgment. Dominik Kundel from the Codex team replied to at least one X post requesting feedback IDs. Similar requests appear in the GitHub comments. Users comply but grow tired of repeating the exercise without visible progress. One commenter summed up the sentiment after a week of radio silence from engineers beyond the standard data requests. The thread continues to collect new logs and reproductions.
Codex still delivers value on straightforward assignments. Simple bug fixes and boilerplate generation work fine. The trouble surfaces when the assignment requires genuine planning or trade-off analysis. That limitation matters. Many teams adopted the agent expecting it to tackle the messy, high-value work that consumes human hours. If the model systematically under-reasons on those jobs, adoption could stall.
Industry watchers on X and 4chan forums have begun to call it “vibe coding” when the agent produces output that feels plausible but lacks depth. The term captures the experience. The code looks right at first glance. Tests may even pass. Yet edge cases break and architectural choices reveal shallowness. Developers end up spending more time reviewing and correcting than they save.
Recent coverage adds urgency. A Facebook post from early July translated the GitHub discussion for Chinese developers and highlighted the AGENTS.md countermeasures. The CSDN article published today walks through root cause theories ranging from reasoning budgets to internal routing. It stops short of firm answers but compiles enough user evidence to suggest the problem is widespread. No new official statement from OpenAI has appeared as of this writing.
The situation leaves engineering teams in a bind. They can dial back to older model variants and lose the speed gains. They can craft ever more elaborate prompt scaffolds to compensate. Or they can wait and hope the next update smooths out the clustering. Many have chosen a mix of all three while keeping a close eye on the original issue thread. The numbers don’t lie. When GPT-5.5 hits exactly 516 reasoning tokens, something inside the system has decided the thinking is done. Whether that decision serves the user remains an open question.

