
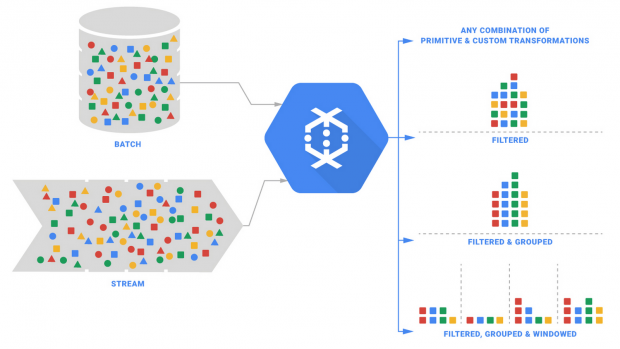
Google announced that it has removed the beta label from Cloud Dataflow, its managed cloud service and programming model for batch and streaming big data processing, and is making it generally available.
“Cloud Dataflow is specifically designed to remove the complexity of developing separate systems for batch and streaming data sources by providing a unified programming model,” Google says in a blog post. “Based on more than a decade of Google innovation, including MapReduce, FlumeJava, and Millwheel, Cloud Dataflow is built to free you from the operational overhead related to large scale cluster management and optimization.”
With Cloud Dataflow, Google promises a “fully managed, fault tolerant, highly available, SLA-backed service” for batch and stream processing as well as a “comprehensive model for balancing correctness, latency, and cost” for dealing with unordered data at “massive” scale. It also promises “great” performance.
“Cloud Dataflow is 2-3x faster and cheaper than Hadoop when evaluating classic MapReduce based pipelines, such as PageRank and WordCount,” the company says. “And with dynamic work rebalancing, Cloud Dataflow effectively optimizes resource utilization which provides additional performance gains without requiring manual intervention.”
They’ve also expanded partner efforts with Tamr, Salesforce, Clearstory, springML, Cloudera, data Artisans.
“Running within the Google Cloud Dataflow service Tamr will enable enterprises to unify, clean, transform and move their data from many diverse sources without investing in expensive data integration expertise or infrastructure,” a spokesperson for Tamr tells WebProNews in an email.
Cloud Dataflow also includes native Cloud Platform integration for Cloud Storage, Cloud Datastore, BigQuery, and Cloud Pub/Sub.
Google also announced general availability of Cloud Pub/Sub. More on this here.
Image via Google

