
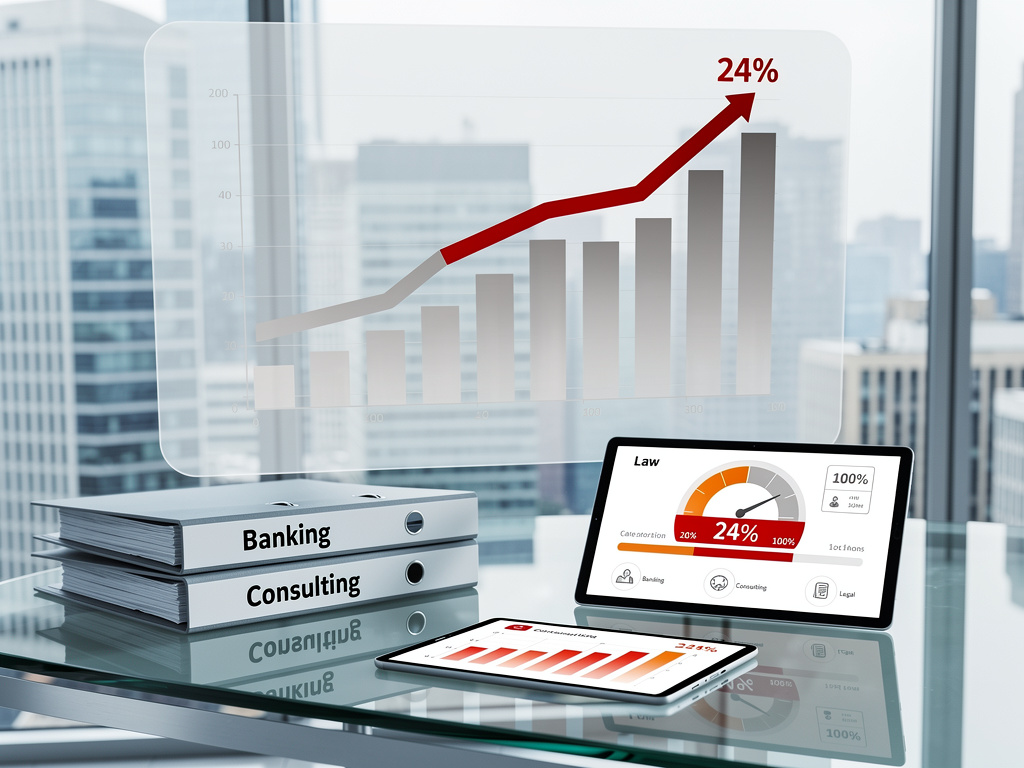
In the high-stakes arena of artificial intelligence, a fresh benchmark is delivering a sobering verdict on the readiness of AI agents to infiltrate white-collar professions. Dubbed APEX-Agents, the evaluation—unveiled by talent platform Mercor—tests leading models on tasks mimicking the daily grind of investment bankers, management consultants, and corporate lawyers. The results are stark: even top performers barely crack 25% success on first-try attempts, underscoring persistent gaps in handling complex, multi-tool workflows.
Developed by Mercor researchers including CEO Brendan Foody, Bertie Vidgen, and Osvald Nitski, APEX-Agents draws from real-world scenarios crafted by experts from firms like Goldman Sachs, McKinsey, and Cravath. As detailed in the arXiv paper, the benchmark comprises 480 tasks across 33 data-rich “worlds,” where agents must navigate simulated Google Workspace environments complete with Slack threads, Google Drive files, spreadsheets, and PDFs. Web search is disabled for reproducibility, forcing reliance on provided materials.
“One of the big changes in this benchmark is that we built out the entire environment, modeled after real professional services,” Foody told TechCrunch. “The way we do our jobs isn’t with one individual giving us all the context in one place. In real life, you’re operating across Slack and Google Drive and all these other tools.”
Tasks That Mirror Professional Realities
Tasks span long-horizon activities, such as a week-long consulting project for a fictitious European oil & gas company focused on cost-cutting, or evaluating EU privacy laws under Article 49 for data exports. Each includes 1-10 pass/fail rubrics defined by professionals to denote “client-ready” outputs. The dataset, openly available under CC-BY at Hugging Face, emphasizes economic value: tasks professionals say take hours, not seconds.
Mercor’s methodology involved surveys of hundreds of experts, followed by veteran consultants and bankers simulating collaborative projects in Google Workspace. Feedback from Harvey AI validated the setup’s fidelity to Fortune 500-level work. Evaluation runs via open-source Archipelago infrastructure on GitHub, using Pass@1 metric—the probability a single run passes all criteria.
Frontier models falter on core knowledge work skills: tracking information across domains, managing ambiguity, and sustaining context. Mercor’s blog notes agents often fail to locate files or maintain workflow coherence, even with high reasoning modes enabled.
Leaderboard: Top Models Fall Short
Gemini 3 Flash (Thinking=High) leads with 24.0% Pass@1, per the arXiv paper, edging GPT-5.2 at 23%, Claude Opus 4.5 and Gemini 3 Pro at around 18%. TechInformed reports these as the highest first-try rates on the 480 tasks. Multiple attempts boost scores—up to 40% with eight tries for the best—but reveal brittleness unfit for production.
“Frontier models successfully complete less than 25% of tasks that would typically take professionals hours,” states Mercor’s announcement. “No model is ready to replace a professional end-to-end.” The leaderboard at Mercor.com/apex tracks progress, inviting labs to compete.
This contrasts with hype around agentic AI. While foundation models excel in research and planning, white-collar automation lags. Foody emphasized to TechCrunch: “I think this is probably the most important topic in the economy. The benchmark is very reflective of the real work that these people do.”
Broader Benchmarks Echo Caution
OpenAI’s GDPval, testing 220 gold-set tasks across 44 occupations like law and engineering, shows models approaching expert quality in under half the cases, per its site. Claude Opus 4.1 led blind evals, with GPT-5 strong on domain knowledge. Yet GDPval focuses on deliverables, not multi-app navigation, highlighting APEX-Agents’ unique rigor.
PwC’s 2026 AI predictions note agentic systems need business-value benchmarks for P&L impact and trust. Korn Ferry’s TA Trends warns of cultural hurdles in human-AI teams, while IDC sees mature AI centers boosting innovation by 20%. X discussions, like Aaron Levie’s post praising Box’s APEX partnership, signal enterprise interest despite gaps.
McKinsey Global Institute posted on X that AI agents could handle 44% of U.S. work hours today, but social skills remain elusive. Duke CFO surveys, cited by fred hickey on X, show minimal AI impact on productivity so far.
Implications for Enterprise Deployment
APEX-Agents challenges Satya Nadella’s 2024 forecast of AI reshaping knowledge work, linked in TechCrunch. Rapid gains—Foody notes intern-like 25% accuracy vs. last year’s 5-10%—suggest acceleration, but current levels demand human oversight.
Josh Bersin Company predicts HR “superagents” cutting staff 30% in 2026, yet G2’s report stresses readiness variances. SiliconANGLE flags integration complexity as a barrier, favoring service providers. Mercor’s open release aims to spur optimization, potentially closing gaps via training-to-test.
As 2026 unfolds, APEX-Agents positions as a pivotal yardstick. “It’s improving really quickly,” Foody told TechCrunch. “That kind of improvement year after year can have an impact so quickly.” Enterprises must weigh pilots against reliability, while labs race to conquer professional workflows.

