
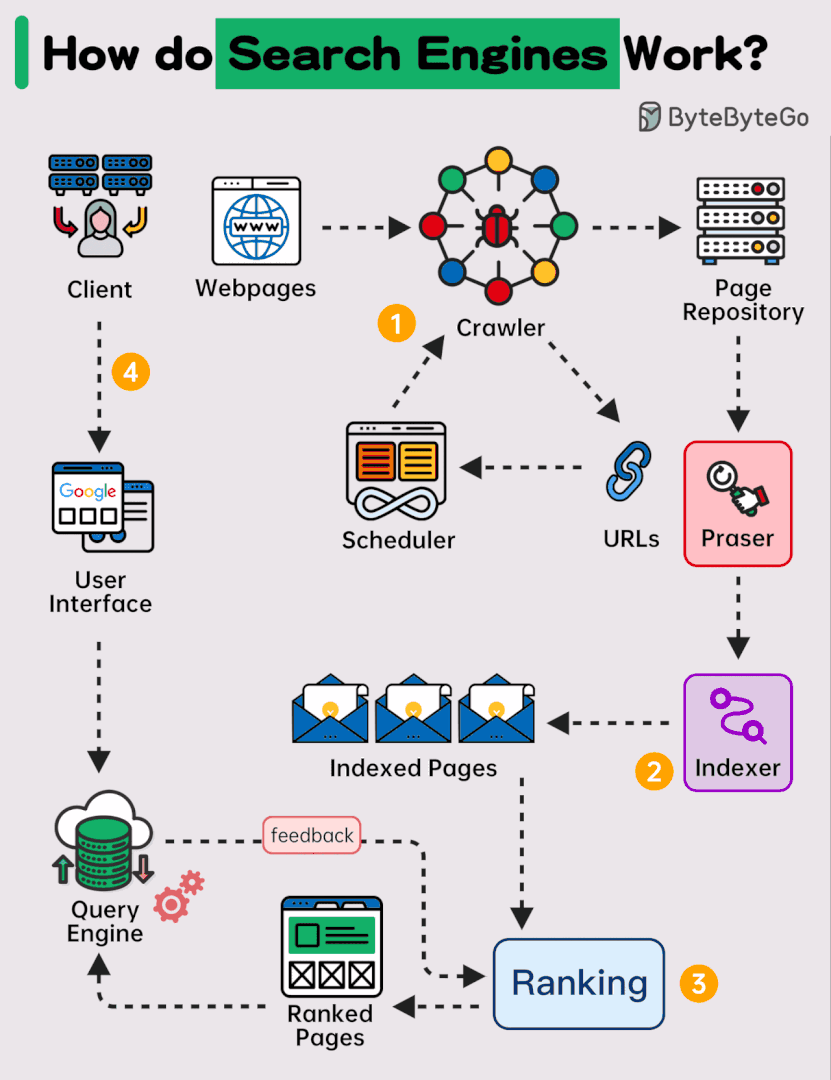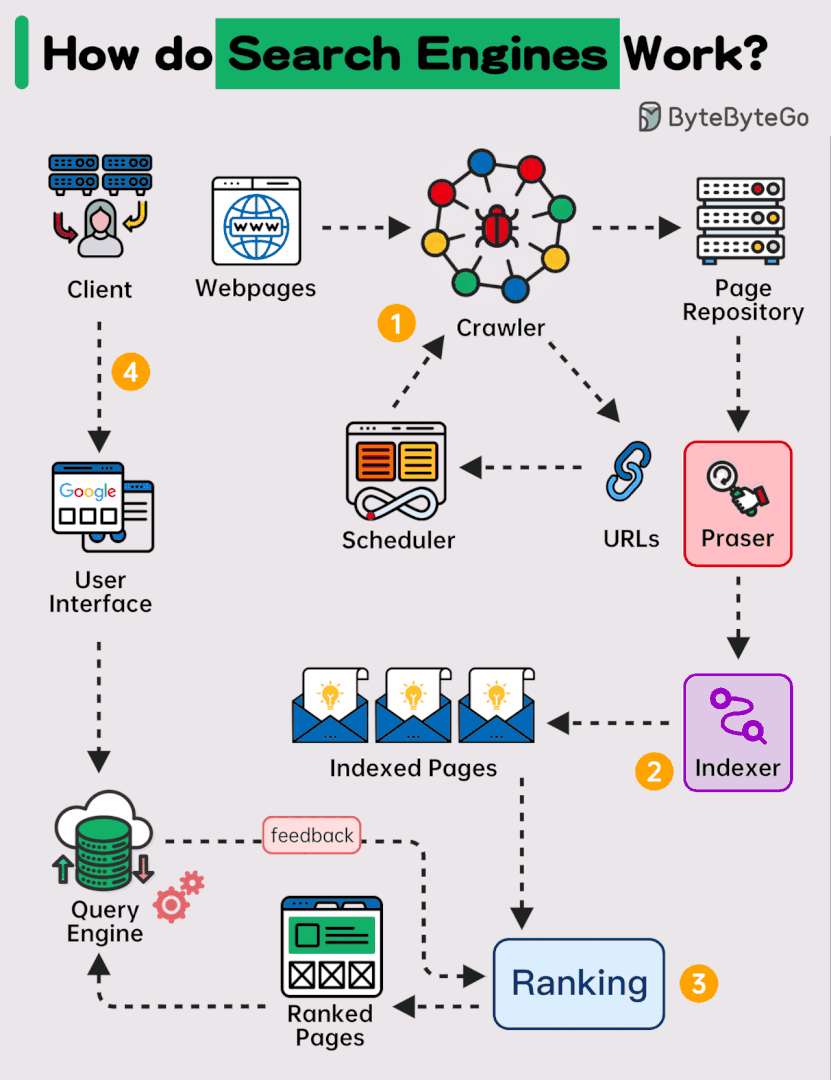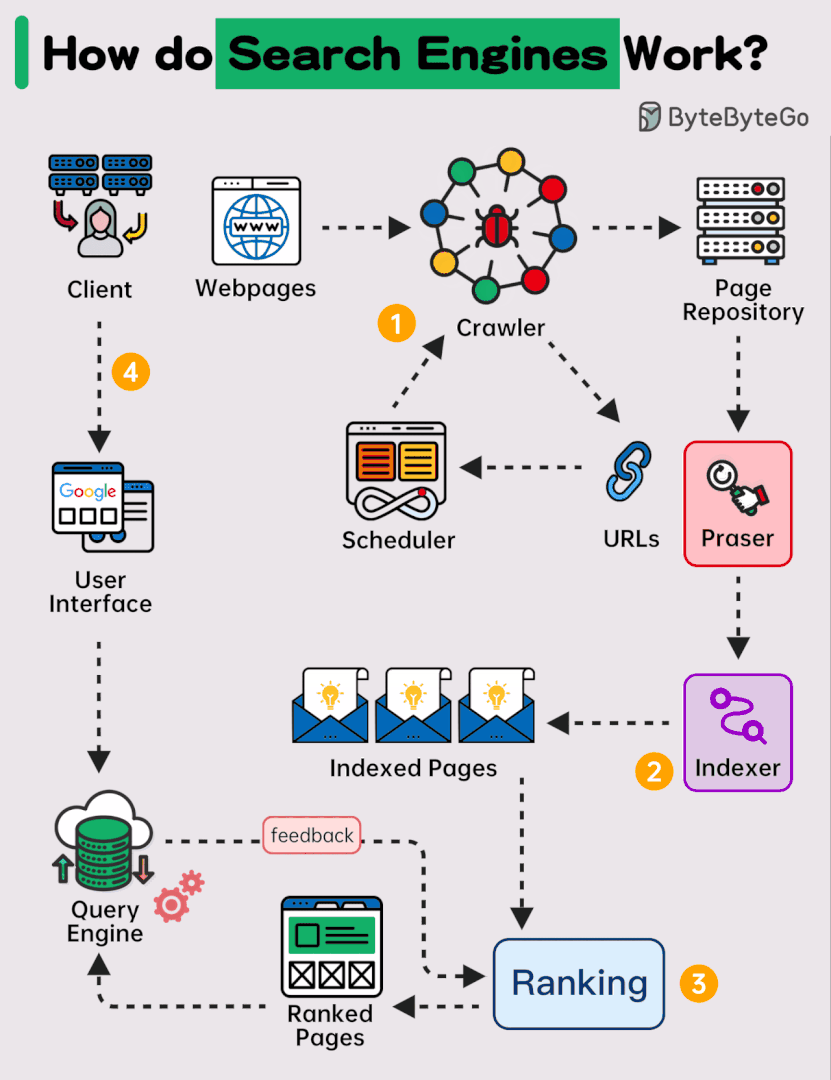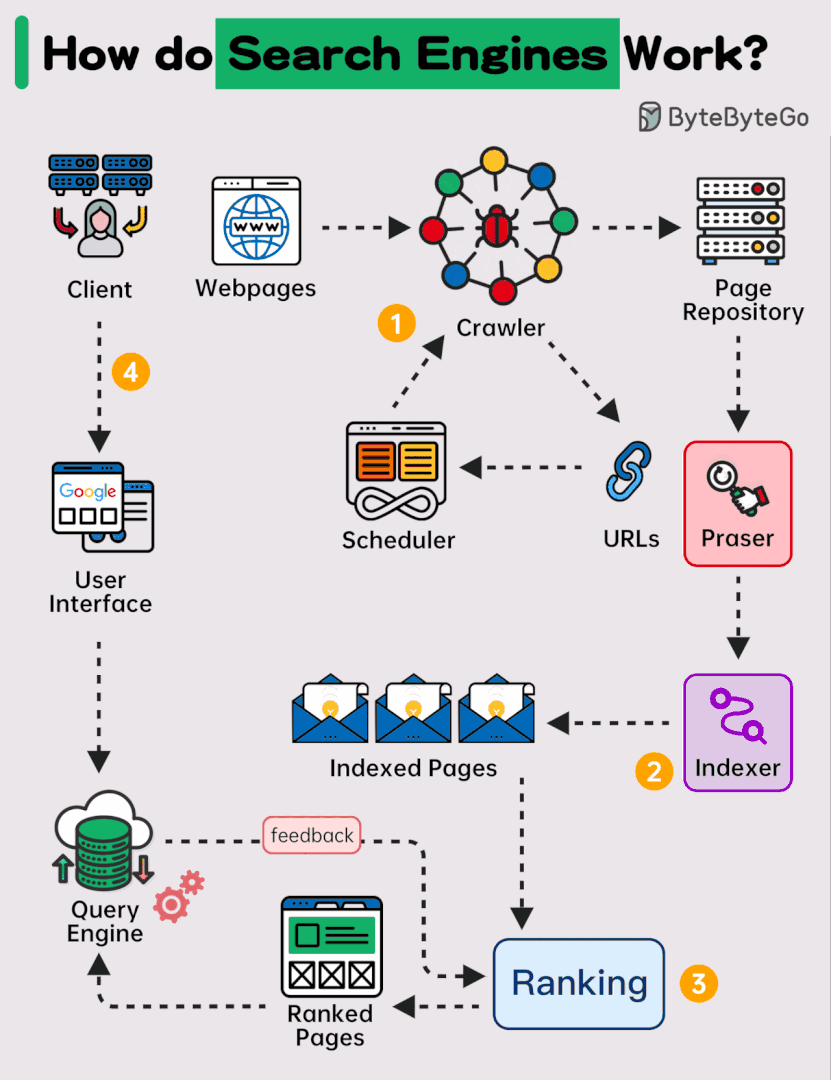
Search engines are a core part of our daily digital experience, guiding us through the vast ocean of information available online. But behind their seamless interface lies an intricate web of technology. The process of delivering search results isn’t just about typing a query into a box; it involves sophisticated algorithms, massive data structures, and the constant interplay of crawling, indexing, and ranking. This article will break down these processes in a way that is both technically deep and accessible.
Crawling: The Internet’s Search Scouts
At the heart of any search engine is its ability to discover and collect content. This is where crawling comes in.
“Crawlers are like the scouts of a search engine,” explains Alex Xu, Co-Founder of ByteByteGo. “They traverse the web, hopping from link to link, gathering URLs and analyzing page content. Without crawlers, search engines would be blind.”
Crawlers begin their work by visiting seed URLs, which are high-traffic websites that are likely to contain valuable links. From there, the web is explored using a combination of breadth-first and depth-first search strategies. The former ensures that multiple sites are visited, while the latter allows deeper exploration of individual websites.
Once a site is identified, crawlers pull in essential information such as titles, keywords, and outbound links. This data forms the foundation for the next steps: indexing and ranking. But with so many websites to crawl, search engines must prioritize efficiently. “Crawl budgets are allocated based on factors like update frequency, link popularity, and overall site quality,” says Xu. This ensures that high-value content is crawled frequently while low-impact pages may only be visited sporadically.
JavaScript-heavy sites have added complexity to the task. Modern websites often rely on dynamic content that isn’t immediately visible to crawlers. Search engines address this by using a two-phase crawl: first, they gather static HTML content, and then they render JavaScript to collect the dynamic elements.
Indexing: Organizing the Web’s Information
Once crawlers gather the raw data, the search engine needs to make sense of it. This is where indexing plays a critical role.
“Indexing is essentially about structuring the web’s content for quick and efficient retrieval,” explains Kristine Schachinger, a technical SEO expert. “It’s about transforming that massive crawl data into something that can be quickly queried when a user enters a search.”
During indexing, the content of each page is broken down into individual words and phrases, which are then analyzed to determine their meaning and importance. This process involves understanding language at a deep level. For example, search engines need to recognize that the words “run,” “running,” and “ran” are all different forms of the same root word. This step is straightforward in languages like English but becomes more complex in languages without clear word boundaries, such as Chinese or Japanese.
Search engines also use an inverted index, a powerful data structure that maps every word to the documents in which it appears. This allows them to quickly locate relevant documents when a user submits a query.
“Compression is key in indexing,” says Schachinger. “With billions of pages to store, search engines need to keep their indexes as lean as possible. This often involves machine learning to dynamically compress data in ways that don’t lose the essence of the content.”
Indexing also assesses the quality of the content. Pages with original, in-depth information are favored, while thin or duplicate content is deprioritized. Links between pages are analyzed to understand relationships and determine which pages carry more authority. This link analysis, in turn, impacts the next stage: ranking.
Ranking: Decoding Relevance and Quality
Ranking is where the magic happens. It’s the process that determines which pages show up at the top of your search results and which are relegated to the bottom.
“Ranking algorithms are at the core of how search engines determine relevance,” says Phil Ye, a strategic sourcing leader who often delves into AI-driven technologies. “These algorithms are complex and evolving constantly, but they fundamentally focus on user satisfaction.”
Search engines evaluate numerous factors when ranking a page, including keyword relevance, content quality, user engagement, and technical aspects like page load speed. The ranking process also considers authority: the more high-quality sites link to a page, the more likely it is to rank well.
But relevance alone isn’t enough. Search engines also assess how well the content satisfies user intent. Are users looking for a specific website, general information, or trying to complete a transaction? Modern ranking systems, like Google’s RankBrain and Neural Matching, use machine learning to refine how these results are prioritized.
One key development in recent years is the use of user engagement signals to influence rankings. “If a lot of people click on a particular result and spend time on that page, that’s a strong signal that the page is delivering value,” says Schachinger. This concept—known as dwell time—has become an increasingly important metric in ranking algorithms.
Additionally, search engines strive to balance personalization with objectivity. While results are often tailored based on a user’s location, search history, and device type, search engines aim to provide diverse perspectives, especially for broad or ambiguous queries.
Querying: Understanding User Intent
When you submit a search query, the search engine doesn’t just match keywords. It works hard to understand your intent.
“Querying is the final challenge,” explains John Mueller, an expert in search technologies. “Search engines break down your query, try to understand what you’re really asking for, and then deliver results that match your intent as closely as possible.”
This process begins with parsing, where the search engine analyzes the individual components of the query. Are you looking for a specific website (a navigational query), general information (an informational query), or trying to buy something (a transactional query)? Based on this categorization, the search engine tailors its results.
Search engines also expand your query by suggesting related terms or correcting spelling mistakes. For example, if you search for “running shoes,” the engine might also retrieve results for “jogging sneakers” or suggest “best running shoes for flat feet” based on popular searches.
Continuous Evolution and Adaptation
Search engines are not static entities. They constantly evolve to meet the demands of users and the complexities of the web. This is particularly true in the age of artificial intelligence, where machine learning models are driving significant advancements in search quality.
“AI models like BERT and MUM are changing the game,” says Ye. “These technologies allow search engines to understand context and semantics in ways that were previously impossible. They can interpret the nuances of natural language and provide more accurate, relevant results.”
As user behavior and web content change, search engines update their algorithms accordingly. This means that maintaining high search visibility requires ongoing effort, whether through improving content quality, keeping up with technical SEO practices, or understanding how emerging technologies impact ranking factors.
The Future of Search
The process of crawling, indexing, ranking, and querying is the backbone of modern search engines. However, the future holds even more advanced systems that blend search with AI-driven personalization and deeper semantic understanding.
As the technology progresses, search engines will continue to focus on delivering the most accurate, relevant, and useful results possible. It’s a constant balancing act between serving individual user needs and maintaining the integrity of the broader search landscape.
Search engines have evolved from simple keyword matchers into sophisticated systems that understand user intent, assess content quality, and adapt to ever-changing web environments. This technical dance of crawling, indexing, and ranking may seem invisible, but it’s what keeps our digital world connected and accessible.

