

LinkedIn announced that it is open sourcing its WhereHows data discovery and lineage portal.
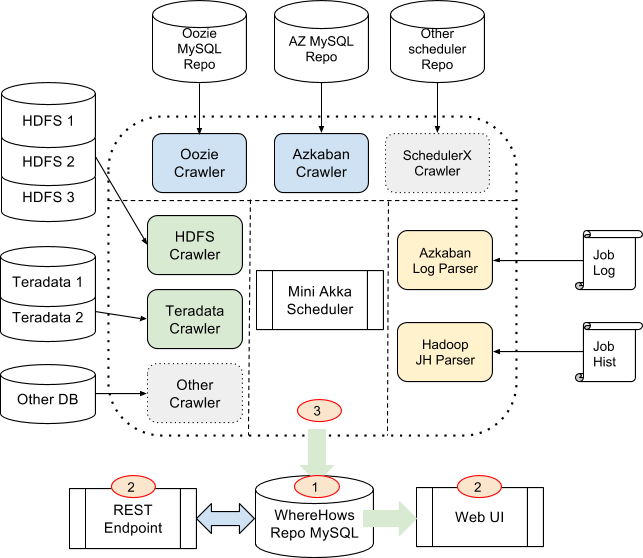
WhereHows is made up of a data repository to store metadata content, a web server that surfaces the data through a UI and an API, and a backend server that periodically fetches metadata from other systems.
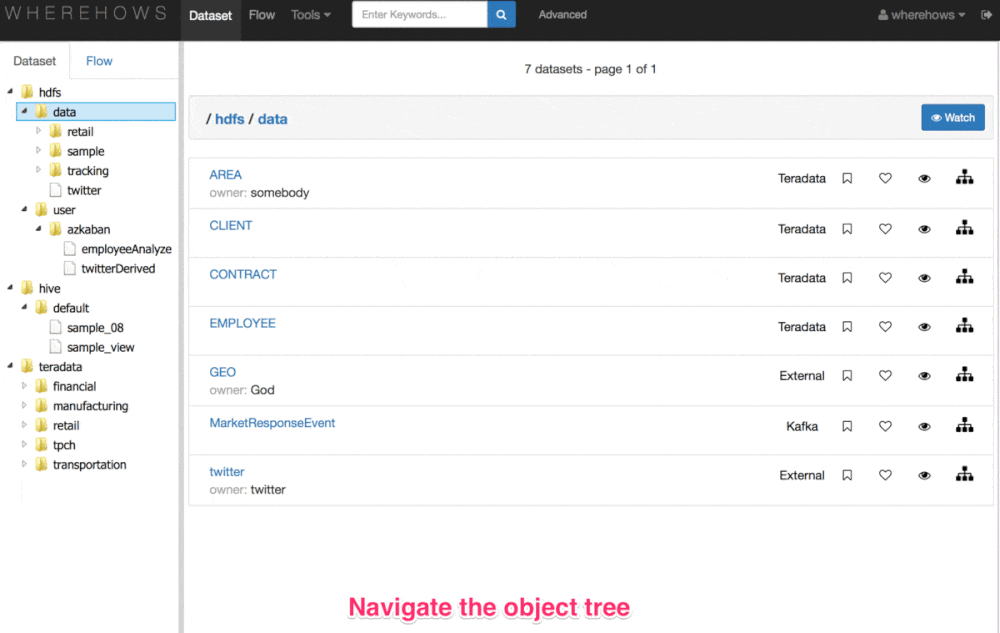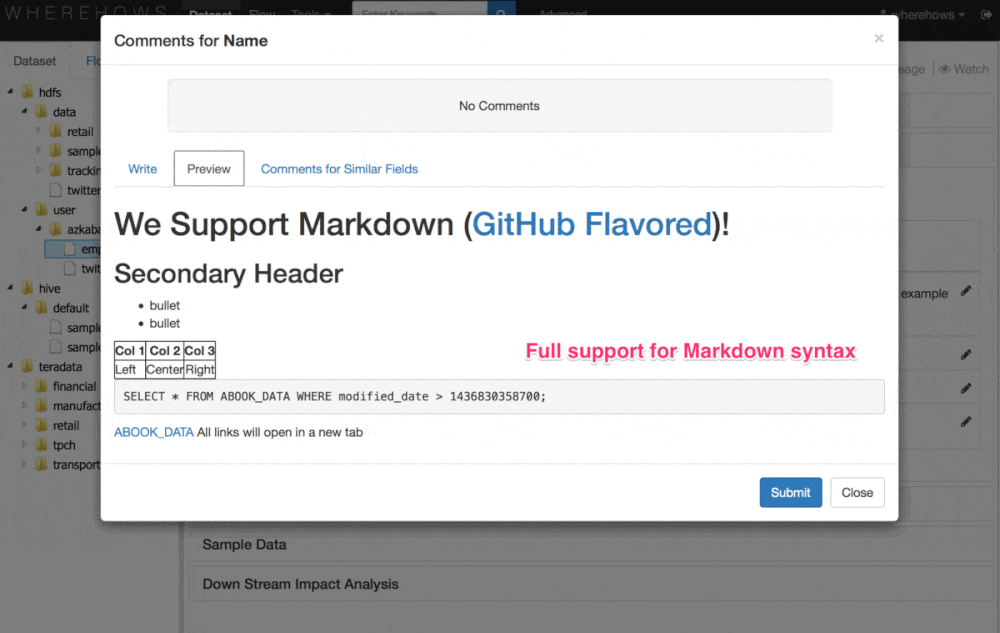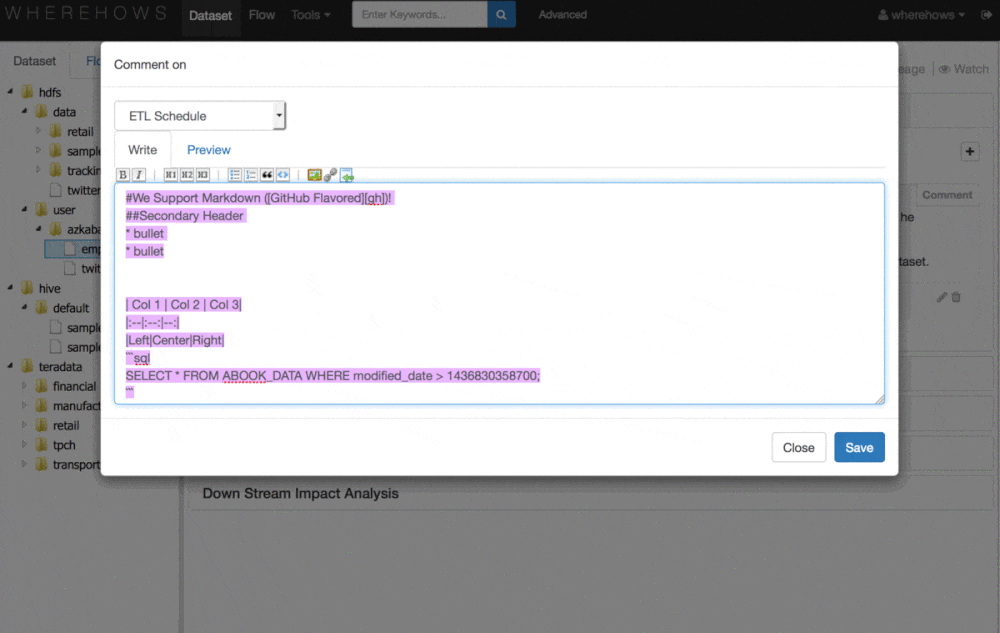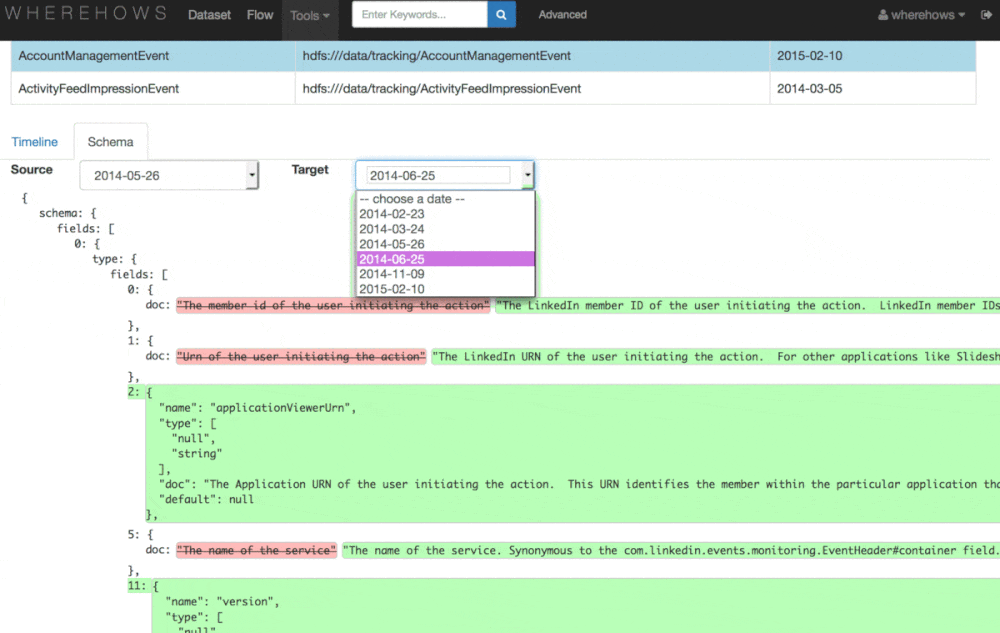
As far as the metadata it collects, this includes the catalog info of datasets (like schema structure, dtasets physical location, timestamp of create/modify, ownership, etc.), operational metadata (like jobs, flows, and execution info), and lineage info metadata (the connection between jobs and datasets).
“At LinkedIn, WhereHows integrates with all our data processing environments and extracts coarse and fine grain metadata from them,” explains LinkedIn’s Eric Sun. “Then, it surfaces this information through two interfaces: (1) a web application that enables navigation, search, lineage visualization, annotation, discussion, and community participation and (2) an API endpoint that empowers automation of other data processes and applications.”
“This enables us to solve problems around data and process lineage, data and process ownership, schema discovery and evolution history, User Defined Function (UDF) and script discovery, operational metadata mashup, and data profiling and cross-cluster comparison,” Sun continues. “In addition to machine-based pattern detection and association between business glossary and dataset, the community participation and collaboration aspect enables us to create a self-maintaining repository of documentation on the entities by encouraging conversations and pride in ownership.”
Read LinkedIn’s full post on the news here for more on how to use the metadata and much more.
There is detailed documentation for each of WhereHows’s components available on Github.
Images via LinkedIn

